
1. 前情提要
近期大量业务发版,后台数据库上了多地部署,数据不一致的情况疯涨,想不到自己读的闲书(DDIA)在排查问题时竟然派上了点作用,这个故事告诉我们没事多看书。
为了化简讲解的复杂度,可以将业务化简为需要在一个 kv 数据库中取出 key,假如没有获取到相应的 value,则随机生成一个值写入数据库中。
为了减少跨地域延迟,数据库是一主多从的,从库多地部署,主从库之间采用异步复制。
2. 分布式下的读写问题
经过排查,发现有以下两个问题。
2.1 并发请求问题
当并发请求的时候,同一用户的多个请求落在了不同的节点上,不同的节点生成了不同的随机值,导致互相覆盖了。
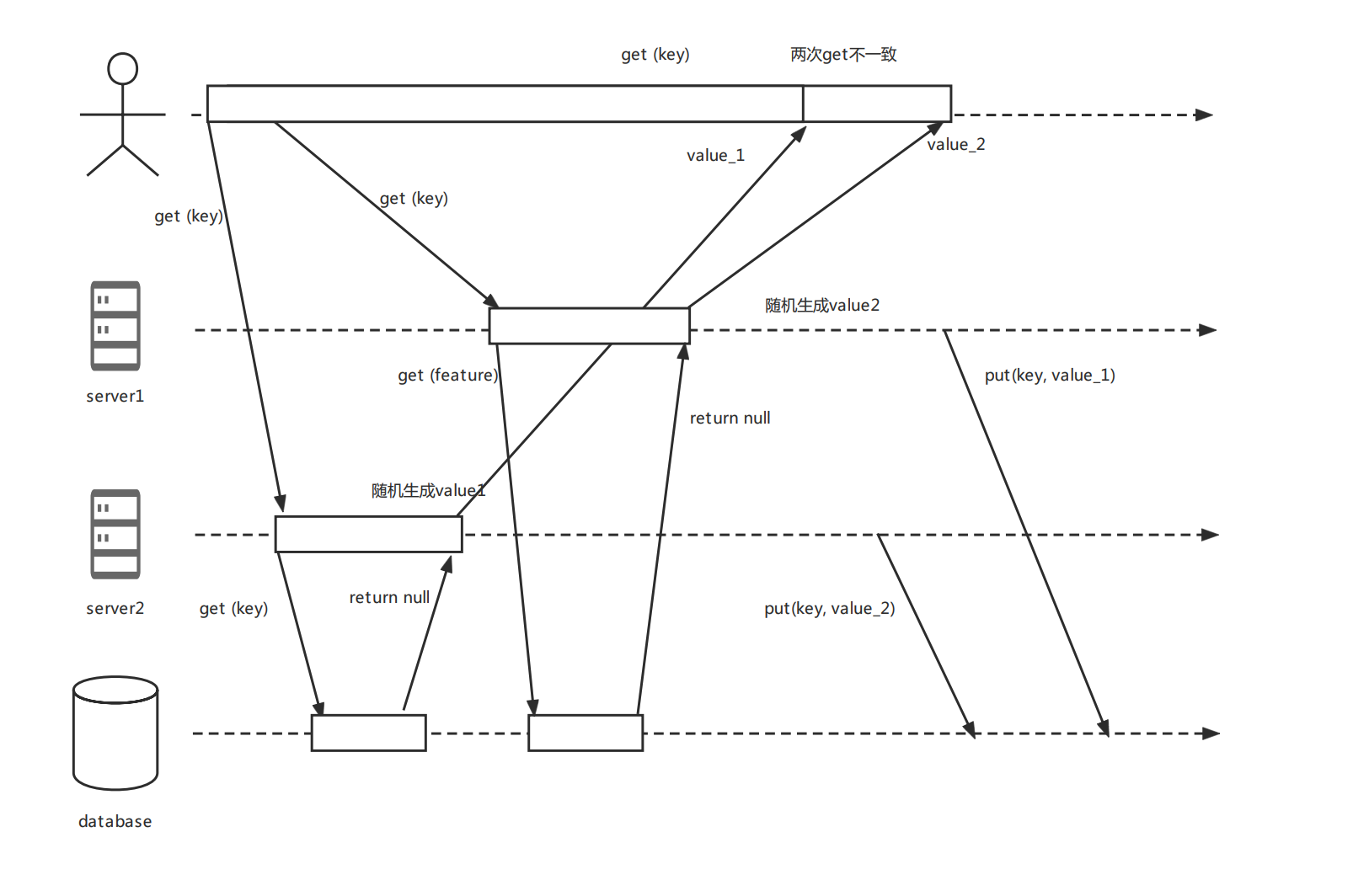
2.2 过期读问题
如果用户在写入后马上就查看数据,则新数据可能尚未到达副本,导致多次分配随机值发生。主从节点不在一个地区时会经常发生。
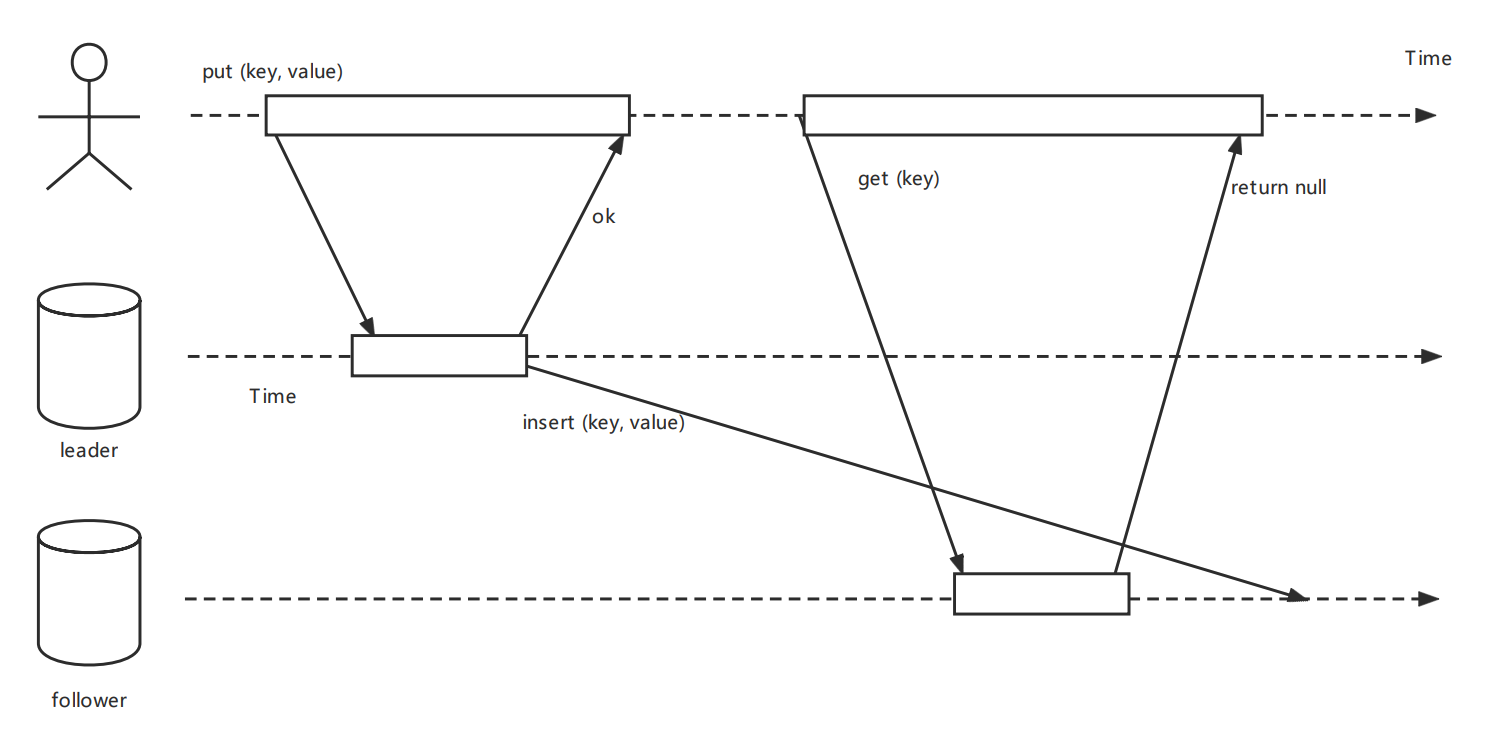
这里多提一下,遇到这个问题一般的解决方案就是
-
强制走主库,将查询请求做分类。通常情况下,我们可以将查询请求分为这么两类:对于必须要拿到最新结果的请求,强制将其发到主库上。
拿朋友圈来说,查看其他人朋友圈是可以出现过期读的,因为即使晚几分钟读到问题也不大。
但是查看自己的朋友圈就必须走主库了。发布完朋友圈马上看自己的朋友圈,如果这个时候出现了过期读,看起来好像是自己发的朋友圈丢失了一样,这就是不可接受的了。
但是如果应用中的大部分内容都只能强制走主库的话,那么复制多个副本就没啥意义了。 -
在客户端跟踪上次更新的时间,在上次更新后的一分钟内,从主库读。
-
监控从库的复制延迟,防止向任何滞后主库超过一分钟的从库发出查询。
假如是本业务,可以直接简单的在从库查不到的时候去主库查询。这个方案有一个缺点,就是无论数据库内没有数据还是同步慢了,都会去查询主库,并且当从库同步较慢时或者有大量新数据要插入时会给主库带来比较大的压力。
想要看更详细的可以去看一下参考文章 DDIA 的复制章节。
3. 解决方案
3.1 使用 CP 组件
最直观的方式就是可以参考 kafka 的 controller 选举,多个同时 broker 去 zookeeper 上创建 /controller 节点,只有创建成功的那个 broker 才会成为控制器。
对应着我们这边就是选择一个创建一个 /key 节点,节点内包含生成的随机值,谁第一个创建成功就分配哪个 随机值。
优点:不会有数据不一致问题
缺点:可扩展性不太行,假如出现大量插入,可能在 zookeeper 或者 etcd 上出现瓶颈。
3.2 使用分布式锁
通过 Redis 加锁,想要进行分配随机数操作必须先拿到锁,插入成功后释放锁,未获取到锁的节点去强制读主库。
// 伪代码
String key = "key";
String value = query(key) // 查询 q36,主从库都能查,查询就近的库
if (value == null) {
lock(key); //获取分布式锁
value = queryMaster(key) // 查询主库
if (value == null) {
value = random();
put(key, value); // put到主库
}
unlock(key)//解锁
}
缺点:方案复杂度高,计算成本高,假如节点拿到锁后崩溃了,会阻塞住随机数的分配直到超时,这个显然是不可接受的。
3.3 Redis lua 脚本
在分配前用生成因子查询一次 Redis,以确认是否有其他服务器已经分配了 value 了,如果其他的服务器已经分配了 value,则拿 Redis 中的 value,如果未分配,则把本服务器分配的 value 写入 Redis 中, 然后返回给客户端。
插入的数据 60 分钟后过期,在 60 分钟后,从数据库大概率已经同步到数据了,后续再请求都能在从数据库中拿到,也就解决了过期读的问题。
为了保证分配的 q36 唯一性,这一系列操作必须是原子的,采用 Redis 的 lua 脚本来实现操作原子性。
redis.call('SET', KEYS[1], ARGV[1], 'NX', 'EX', '3600') return redis.call('GET', KEYS[1])
必须使用 Lua 脚本让操作是原子性的,假如不是原子性的,仍然会出现并发 GET 到空,然后写入不同 q36 的情况
优点
优点:AP 架构,性能高,可扩展性强,目前大业务发版也能非常轻松的支撑,后续即使撑不住也只需扩容 Redis 分片即可,不需要额外引入新组件。
同时阻止了数据库并发操作,降低了数据库的负载。非阻塞操作,性能相比分布式锁高。
妥协点
由于需要保障性能和可用性,对一致性作出了妥协。
方案仍然在非常极端的情况下才会出现数据不一致的问题。不过可以通过离线补偿,最后都会达到最终一致性。
Redis 主从切换时,写入的数据可能会丢失,从节点被选举出来的时候,这个时候有并发生成,也会出现不一致情况。
Redis 数据库挂掉时,仍然需要生成随机数,这个时候会将异常日志落库到 Hive 中,后续通过日志对数据进行补偿。
极端情况下,比如说一小时主库都没有把数据同步给从库,此时 Redis 中的数据过期了,仍然会出现过期读的情况。
参考文章:
本文由 鸡米 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Dec 10,2022