
在我高中的时候,有自学过一段时间的口琴。我同桌吉他玩的比较好,他看到以后也去学了一下,在两个月的时间内就吹的比我吹了半年的水平还高不少了。
再后来我发现无论是吉他,钢琴还是其他乐器,都是有同一套的乐理知识,包括对于节拍的掌握,这部分知识在不同的乐器之间都能迁移。
这系列博客就是希望介绍一些在后端中不变的东西,也就是后端组件中的"乐理知识",希望读者在读完以后能抓住不变的东西,在学习新的组件的时候会这样的感觉:诶,这个我好像在哪里看到过。
正如 ddia 上写的
数据库的复制算得上是老生常谈了 ——70年代研究得出的基本原则至今没有太大变化
我们的第一个问题就是:写入的数据如何做到不丢的呢?
相信这部分的讨论一定不会脱离,预写日志,刷盘,多节点同步
通过预写日志与刷盘控制来保障单机下的不丢失,通过多个节点同步数据保障集群下的数据不丢失。
当然这也分很多个流派,比如说 kafka 就不推荐通过落盘而是推荐主从同步到多个节点中,pulsar 则通过直接写入到多个节点来保障持久性。
WAL
WAL(Write Ahead Log) 预写日志,用于保证数据操作持久性与提升性能。
上面是能查到比较通用的说明,但是实际上还有其他好处,比如说存储数据需要攒一批才落盘,但是在这期间的写入也不能丢,在后面我们会看到这样的组件。
理论上只需要每次写入操作的时候等数据完全落盘后再返回成功给 Client 就很难有丢失数据的问题了(当然排除断电数据操作到一半磁盘损坏了),但是因为这样性能太差了绝大部分的中间件都没用这样干。
众所周知 MySQL InnoDB 存储基于 B+ 树的聚簇索引,全部数据都存在 B+ 树的叶子节点上,那么假如想保证每次 insert 给客户端返回成功后不会丢数据,那么需要:
- Client 发起请求插入
- MySQL 找到相应的磁盘位置,操作 B+ 树(当然这里需要 double write,要不然操作到一半断电数据就损坏了),并且刷盘完成
- 返回给客户端插入成功
这样每次请求都是一次对硬盘的随机写,性能非常差。
为了提升性能,绝大部分的组件都是通过预写日志把随机写转成顺序写。
只要预写日志写入完成后即可返回写入成功给客户端,大大提升了写入性能。
让我们看一下实际上架构是什么样子的,只需要注意下面的 Redo Log 与 Change Buffer 部分就行。
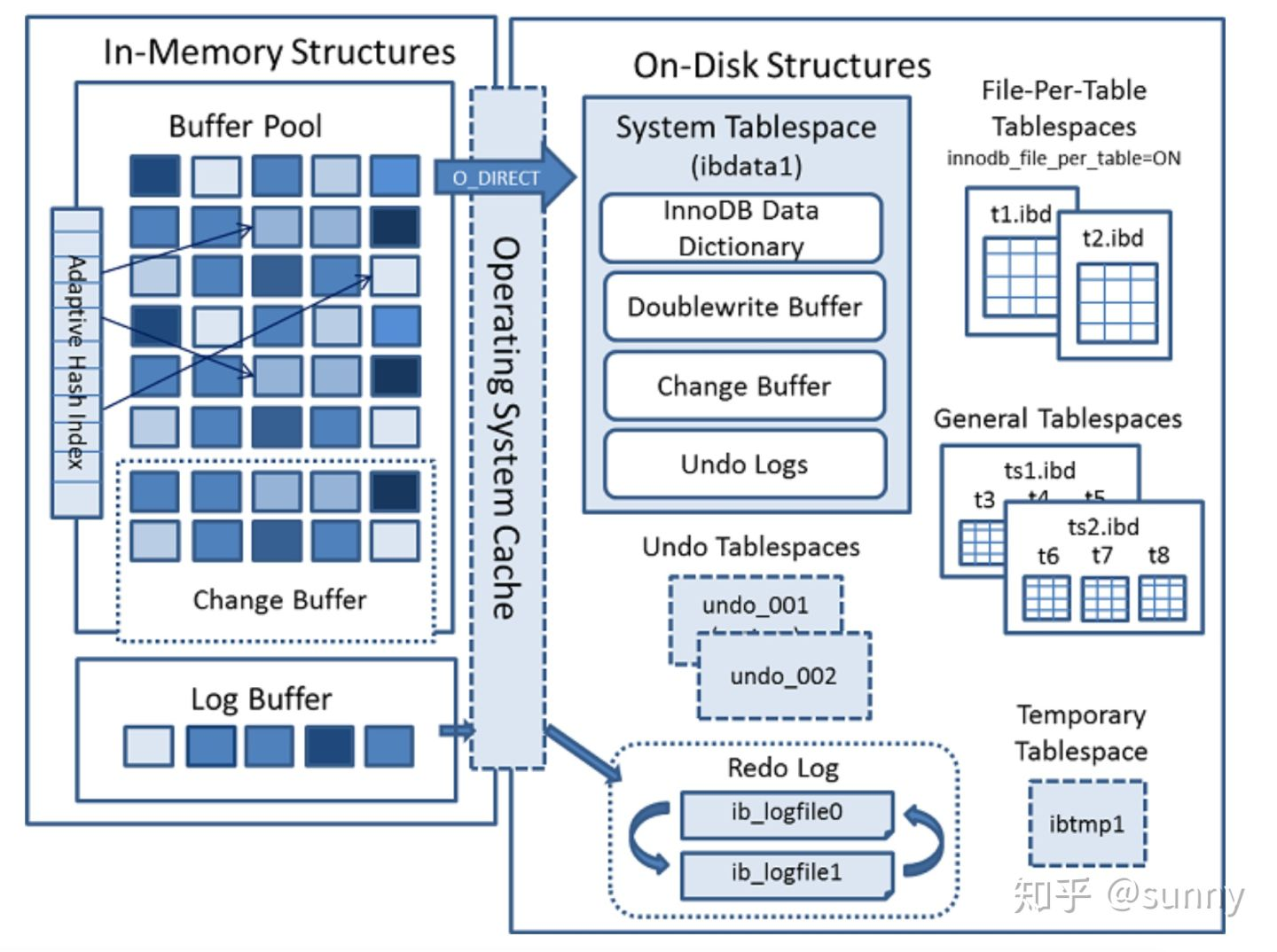
- 客户端请求插入
- 写预写日志 (在 MySQL 中就是记录具体对硬盘哪个位置进行什么操作的 Redo Log)
- 写缓存,写到 Buffer Pool 中,写完缓存在数据真正写到 B+树前,其他客户端就能查到更改后的数据了
- 返回给客户端插入成功
- 后台线程定期把更改缓存的数据落盘,落盘完成后就可以清理日志了
- 当还未落盘其他的客户端需要读的时候,需要把硬盘里的数据读到 PageCache,然后把 Change Buffer 的记录应用上去
- 假如数据落盘前,MySQL 进程挂了,那么由于硬盘里保存着 WAL 日志,只要下次启动进程的时候,重放 Redo 日志把更改记录应用到硬盘上。
绝大部分的架构基本上都一样,写操作写 WAL,一层缓存层用于暂存修改后的数据。后台线程定期刷盘并且清理 WAL,当进程意外退出时重放 WAL 日志恢复数据。
leveldb
leveldb 是一个基于 LSM-Tree 的单机 kv 数据库,有非常多的组件依赖于它的改进版本 RocksDB,比如说 Pika,Flink,Pulsar 等。
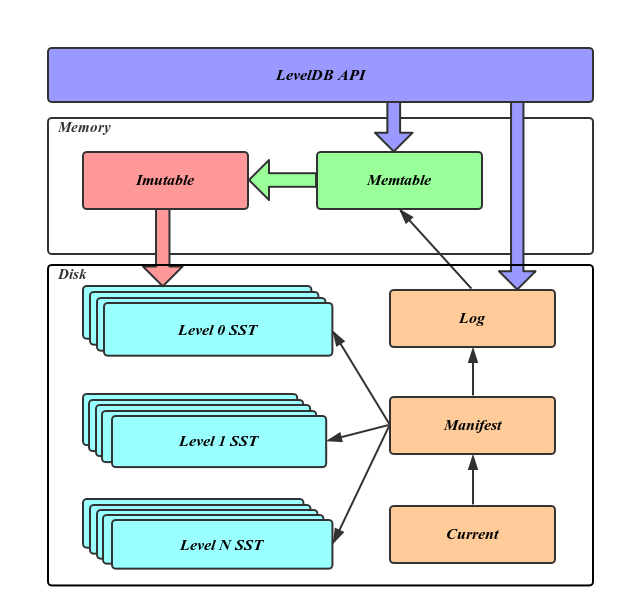
写 WAL 是为了攒一批数据,顺序写入盘中(变成 SSTABLE,以方便快速查找),但是假如落盘前进程被重启了,这部分数据又不能被丢了。
- **Log文件:**写Memtable前会先写Log文件,Log通过append的方式顺序写入。Log的存在使得机器宕机导致的内存数据丢失得以恢复;
- **Memtable:**内存数据结构,跳表实现,新的数据会首先写入这里,查找也会先查这里再去查后续的;
- **Immutable Memtable:**达到Memtable设置的容量上限后,Memtable会变为Immutable为之后向SST文件的归并做准备,顾名思义,Immutable Mumtable不再接受用户写入,同时会有新的 Memtable 生成;
- **SST文件:**磁盘数据存储文件。分为Level 0到Level N多层,每一层包含多个SST文件;文件内数据有序,可以加速查找。
Bookkeeper
Pulsar 底层基于 Bookkeeper,同样是一层缓存,写 wal 日志,定期合并 Memtable 的数据落库到硬盘上。
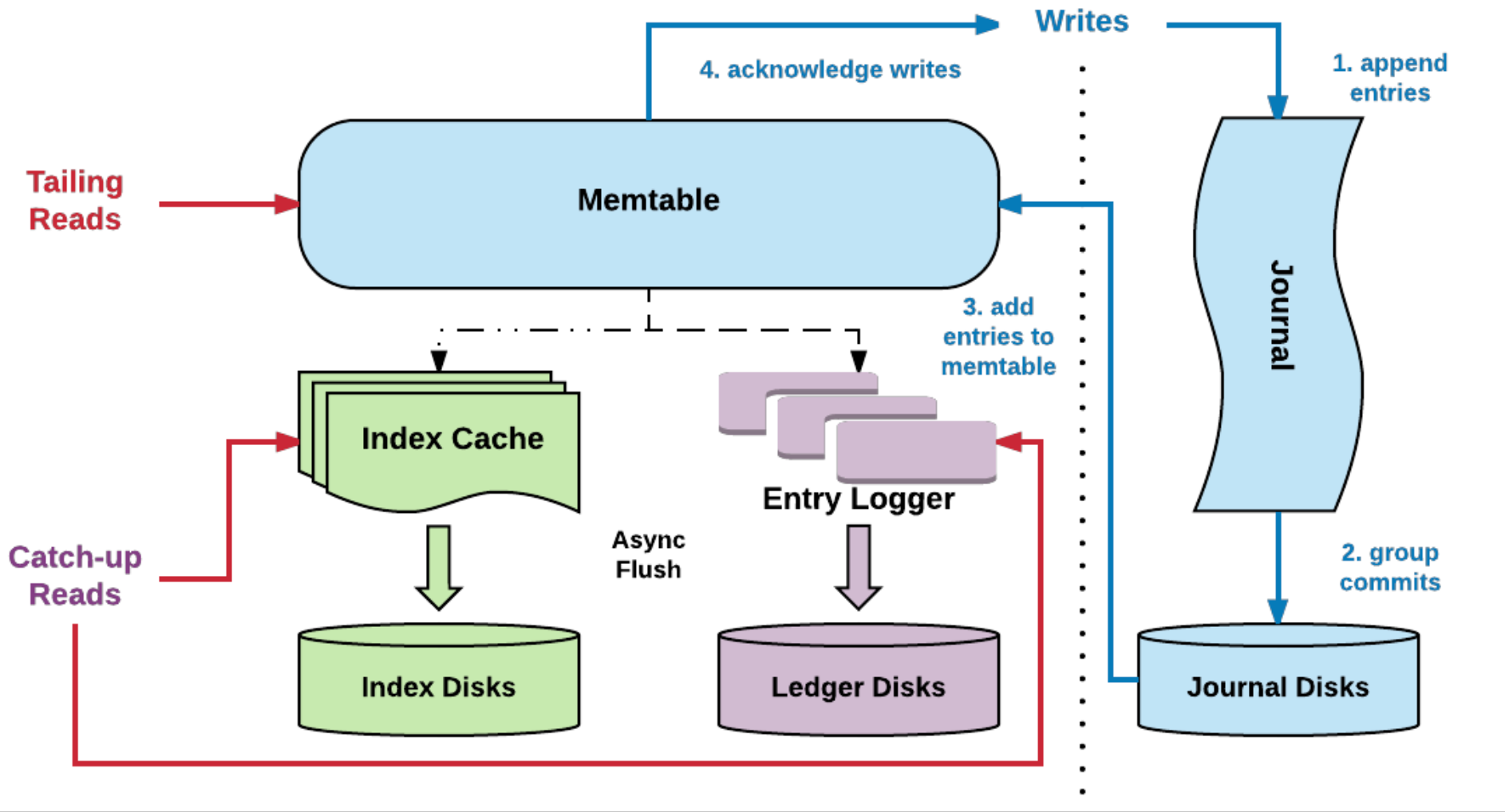
写入时,不但会写入到 Journal 中,还会写入到缓存(memtable)中,这样如果有查询会优先查找到缓存中的数据。后台会定期会做刷盘(刷盘前会做排序,通过 聚合+排序 优化读取性能);
Redis
这里有一个很像 wal 日志的 Redis 的 AOF 日志,不过这个是写后日志,就是先写内存,返回给客户端成功,同时异步刷盘。
好处是不会因为刷盘阻塞,坏处是即使写入后客户端返回成功了,也没办法保证已经落盘了,因为可能返回成功后还未落盘进程就挂掉了,所以 Redis 并不能 100% 的保证持久化(不过绝大多数场景下都足够了)。
刷盘的权衡
预写日志写好了就一定落盘了吗?日志落盘虽然是顺序写非常快,但是仍然有可以权衡的地方。
在进程执行 write 的时候,实际上是将数据写到了内核的 PageCache 中,由于 PageCache 是操作系统的缓存,所以即使进程在写后崩溃了,只要操作系统没有崩溃,数据最终还是会落盘的。内核会挑选适合的时机调用 fsync 刷盘。但是如果写到 PageCache 后还未 fsync,操作系统崩溃了(比如说机房断电了),那么数据就会丢失。
这里注意其实写 pagecache 也是写到内存中,对性能并没有很大的影响
绝大部分的中间件需要权衡性能与可靠性,并且会提供性能从低到高以下几种方式:
每秒写 PageCache 并且刷盘:这样当数据库进程挂了会丢一秒的数据
每次都写 PageCache,刷盘交给操作系统决定,这样数据库进程挂了不会丢数据,但是操作系统挂了会丢掉全部未刷盘的数据
每次都写 PageCache 每秒刷盘:进程挂了不会有影响,但是操作系统挂了会丢一秒的数据
每次都写 PageCache 并且刷盘:性能最低,可靠性最好,无论操作系统挂了还是进程挂了都不会丢数据
其实这里业界不同的中间件实现也有一些不同的地方,这里我们挑几个组件讲一下。
通过服务端配置控制
MySQL 通过 innodb_flush_log_at_trx_commit 来控制 Redo Log
0(延迟写):事务提交时不会将 redo log buffer 中日志写入到 os buffer,而是每秒写入 os buffer 并调用 fsync()写入到 redo log file 中。也就是说设置为 0 时是(大约)每秒刷新写入到磁盘中的,当系统崩溃,会丢失 1 秒钟的数据。
1(实时写,实时刷):事务每次提交都会将 redo log buffer 中的日志写入 os buffer 并调用 fsync()刷到 redo log file 中。这种方式即使系统崩溃也不会丢失任何数据,但是因为每次提交都写入磁盘,IO 的性能较差。
2(实时写,延迟刷):每次提交都仅写入到 os buffer,然后是每秒调用 fsync() 将 os buffer 中的日志写入到 redo log file。这种情况下 mysql 崩溃了也不会丢失数据,但是系统崩溃了会丢数据。
Kafka 是通在 broker 端还有两个参数 log.flush.interval.messages 和 log.flush.interval.ms,用来调整同步刷盘的策略,默认是不做控制而交由操作系统本身来进行处理。
log.flush.interval.messages:每几条消息刷一次盘
log.flush.interval.ms:每间隔多少ms刷一次盘
通过客户端配置控制
MongoDB 是里面最灵活的,控制刷盘的参数可以通过请求携带的参数控制,每一个请求都可以单独配置刷盘策略,在同一个 client 上的不同插入语句可以有不同的刷盘策略。
MongoDB 只提供了一个配置来控制日志每多少 ms 刷一次盘,默认配置是 100,也就是说如果没有进行任何干预的情况下,MongoDB 最多会丢 100ms 的写入数据。
它提供了一个新的概念 Write Concern ,简单来说就是可以通过写入附带的参数来控制这个请求是否应该刷盘。
比如说当在某个请求写入可靠性要求非常高的情况下,就可以配置 w:true 来控制这个请求需要强制对 wal 刷盘。其余请求要求不高就可以不配置这个。
多节点同步
虽然通过前面的方式能在单机上不丢数据,但是如果写入成功后单机挂掉了那么数据还是没了。
一些组件虽然会使用预写日志,其实官方更推荐依赖于集群之间的复制来保障数据不会丢失。还有一些组件通过直接写多份数据来保障数据的持久性。
复制
复制细节,数据一致性,可用性的权衡后续会展开另外写一篇文章,这里只讲一下数据如何通过复制与数据可靠性的关系。
复制分为异步,同步,半同步。
- 异步:成功写入主节点后,异步复制从节点还未复制到数据的时候出现了主从切换,数据就丢了。
- 同步:当写入同步到全部从节点才返回成功则是同步复制,同步复制会导致某一个从节点挂了整个集群不可用。
- 半同步:从主节点同步到部分从节点成功就给客户端返回就是半同步复制,如果主节点挂掉了,选主也只能从已经同步到最新数据的从节点上选,否则仍然和异步复制一样会丢数据。
MySQL 通过配置服务端的参数来控制,同步复制,半同步复制。
Kafka 能通过 Producer 上的 ack 参数来控制同步还是半同步复制,并且在 broker 上配置半同步最少同步到多少个节点上,相比之下更灵活些。
ack = 1 时只需要主节点确认写入成功后,不需要等同步数据就会返回写入成功
ack = all 时会同步到全部的 ISR(未落后的从节点) 中,才能算是写入成功
服务端侧则通过控制写入最小副本数min.insync.replicas 来实现半同步复制最少需要复制到几个节点。
MongoDB 则仍然是最灵活的一个,能通过写入参数来控制最少需要同步到几个节点上,只需要在写入的时候配置W: x 就能控制主节点复制到 x 个节点后才算写入成功。
主从复制选主的讨论
kafka broker 可以通过 unclean.leader.election.enable 控制选主的时候是否选择落后的节点来权衡可用性和持久性,当开启只选 ISR 时,选主只能选择已经同步到全部数据的节点,假如没有这样的节点会导致集群不可用。
MongoDB 有一个有趣的回滚策略可以讲一下:
假如向主节点插入 A,B 两个文档,A 同步到从节点,B 还未同步,此时出现了 failover
从节点被选为主节点,并且继续接收写入 C,此时新的主节点上有 A,C 两个文档
后续主节点重新加入集群,此时主节点会到新的主节点上去找到同步点,发现 B 未同步,此时会回滚 B 文档并且打印 B 文档,将新的文档 C 同步过来,此时主从节点都只有 A,C两个文档,B 文档在日志中等待人工处理。
Quorum
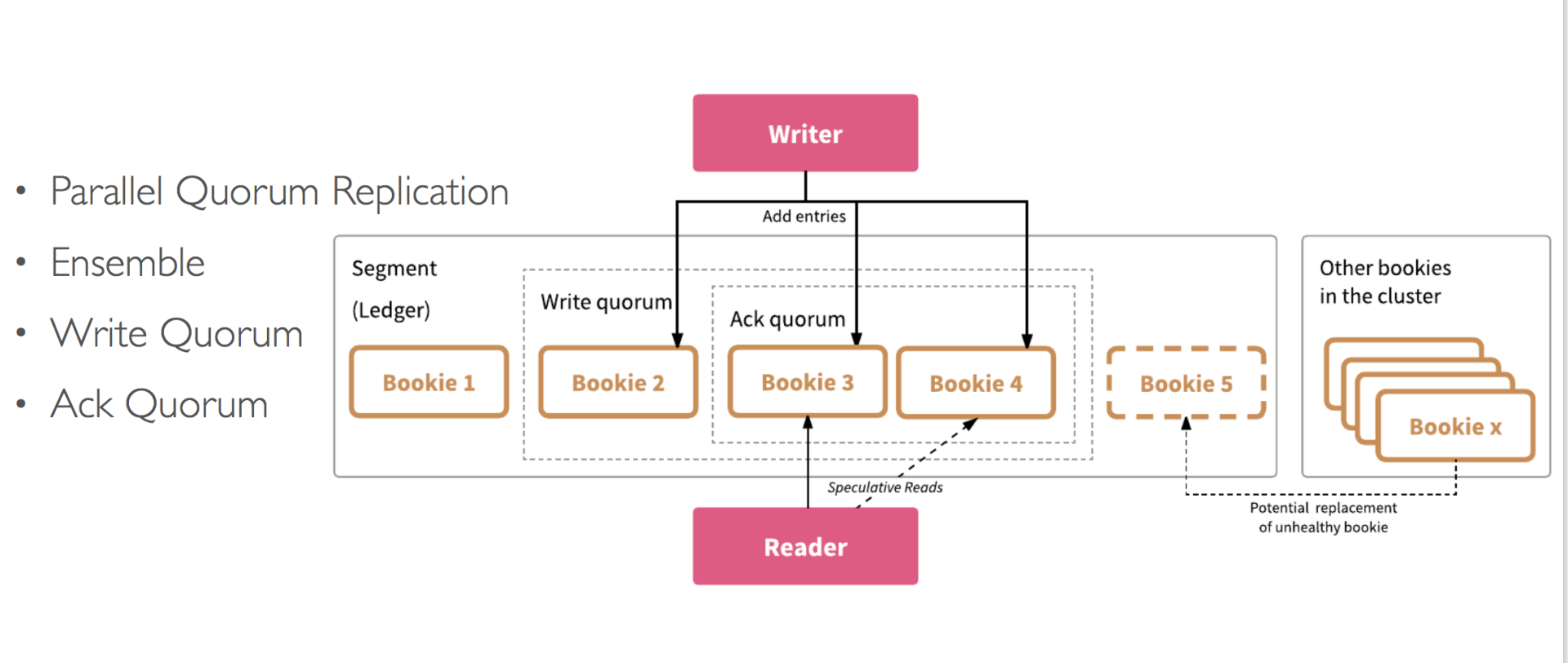
与写到主节点再复制到多个从节点不同的是,还可以通过直接写入多个节点来保证数据的可靠性。感兴趣的可以看下 Quorum 算法,这里就只大概讲一下。
简单来说就是加入我们有 N 个节点,写入的时候带上 W 参数,代表需要直接写入几个节点上,当返回写入成功的时候,就已经是同步到 W 个节点上了。
当读取的时候带上 R 参数,一次性读取 R 个副本,才会认为是数据读取成功。
当 W + R > N 的时候则读的时候最少能读一份最新的数据,那么直接取最新的数据就好了。
这里拿 pulsar 举例,可以看到与主从同步区别就是并不是与主节点交互,而是直接向多个相同节点去写入了。
参考
MongoDB Documentation
BookKeeper concepts and architecture
BookKeeper 原理浅谈
MySQL 实战 45 讲
leveldb-handbook
《深入理解Kafka:核心设计与实践原理》
《MongoDB 权威指南》A
《Designing Data-Intensive Application》
本文由 鸡米 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Nov 22,2023